GPU Benchmarks
These benchmarks help users choose the optimal GPU SKU for running their AI models with KAITO. We compare performance characteristics across different GPU types to guide cost-effective hardware selection.
Test Setup
Infrastructure Configuration
We established a dedicated Kubernetes cluster with KAITO deployed to conduct comprehensive GPU performance benchmarks. The testing infrastructure was configured to evaluate three distinct GPU types: NVIDIA A10, A100, and H100, each representing different performance tiers and cost points in the GPU ecosystem.
GPU Selection Rationale
Due to memory and compute constraints, the A10 GPU was evaluated separately using lighter model configurations, as it lacks sufficient resources to handle the larger workloads tested on the A100 and H100 GPUs. The primary comparison focused on A100 and H100 performance characteristics using two representative models: phi-4-mini-instruct and llama-3.1-8b-instruct.
Benchmark Framework
All performance tests utilized vLLM by running the official benchmark_serving.py script, which provides standardized metrics for evaluating inference server performance. This tool measures critical performance indicators including:
- Time to First Token (TTFT): How long the user must wait until the model begins to deliver a response.
- Inter-Token Latency (ITL): How fast the model generates subsequent tokens after it begins its response.
Model Configurations
We tested the models Phi-4-mini-instruct and Llama-3.1-8B-Instruct. The following fields were configured:
- Requests Per Second (RPS): Total throughput capacity with latency in powers of two, such as 1, 2, 4, etc. up to 64 for larger GPUs, indicated by the
--request-rateflag. - Max Concurrency: The maximum number of simultaneous requests the server can handle, configured with the
--max-concurrencyflag. It was set to 200 for the A100 and H100 tests and 50 for the A10 tests. These values were selected in order to set a ceiling high enough that it will not bottleneck the GPU. - Random Input Length: The length of the input prompts, configured with the
--random-input-lenflag. This value was increased for larger models/GPUs that could handle an increased workload. A smaller value could represent a conversation workload, while a larger value could represent a document or source code. - Random Output Length: The length of the expected output responses, configured with the
--random-output-lenflag. - Number of prompts: We configured each test to run for 60 seconds, so with the number of prompts was set to
$RATE * 60.
Phi-4 Mini Instruct Model
The microsoft/Phi-4-mini-instruct model was tested with the following configuration with
python benchmark_serving.py \
--backend vllm \
--model microsoft/Phi-4-mini-instruct \
--served-model-name phi-4-mini-instruct \
--base-url http://localhost:8000 \
--endpoint /v1/completions \
--num-prompts $NUM_PROMPTS \
--request-rate $RATE \
--max-concurrency 200 \
--random-input-len 200 \
--random-output-len 200 \
--dataset-name random \
--ignore-eos \
--save-result \
--result-dir "./out/$GPU"
Test Parameters:
- Input Token Length: 200 tokens (simulating medium-length user queries)
- Output Token Length: 200 tokens (representing typical conversational responses)
- Use Case: Optimized for interactive chat applications and content generation
- Load Pattern: Variable request rates from 1 to 64 QPS
Llama 3.1 8B Instruct Model
The meta-llama/Llama-3.1-8B-Instruct model was configured for high-throughput, short-response scenarios:
python benchmark_serving.py \
--backend vllm \
--model meta-llama/Llama-3.1-8B-Instruct \
--served-model-name llama-3.1-8b-instruct \
--base-url http://localhost:8000 \
--endpoint /v1/completions \
--num-prompts $NUM_PROMPTS \
--request-rate $RATE \
--max-concurrency 200 \
--random-input-len 1000 \
--random-output-len 200 \
--dataset-name random \
--ignore-eos \
--save-result \
--result-dir "./out/$GPU"
Test Parameters:
- Input Token Length: 1000 tokens
- Output Token Length: 200 tokens
- Use Case: Optimized for large context understanding with minimal output generation
- Load Pattern: Variable request rates from 1 to 64 QPS
A10 GPU
Since the A10 GPU was not powerful enough to run larger models, higher input/output lengths, or higher QPS, we tested it individually with lower settings as to not skew the results of the other GPUs.
- The QPS ranged in powers of two from 1 to 16 instead of 64.
- For Phi 4 Mini and Llama 3.1 8B, the max concurrency was set to 50 instead of 200.
Testing Methodology
Benchmark Results
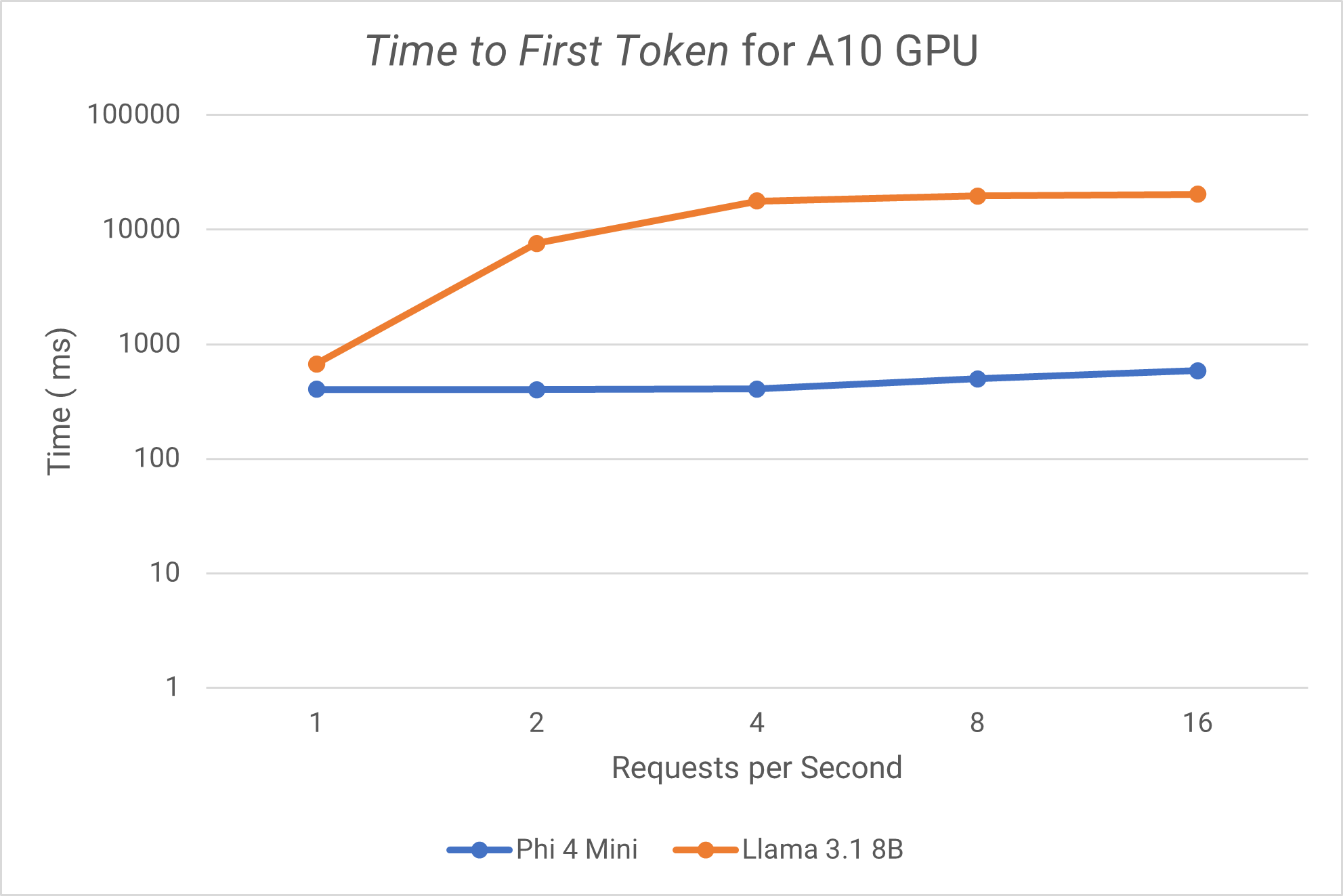
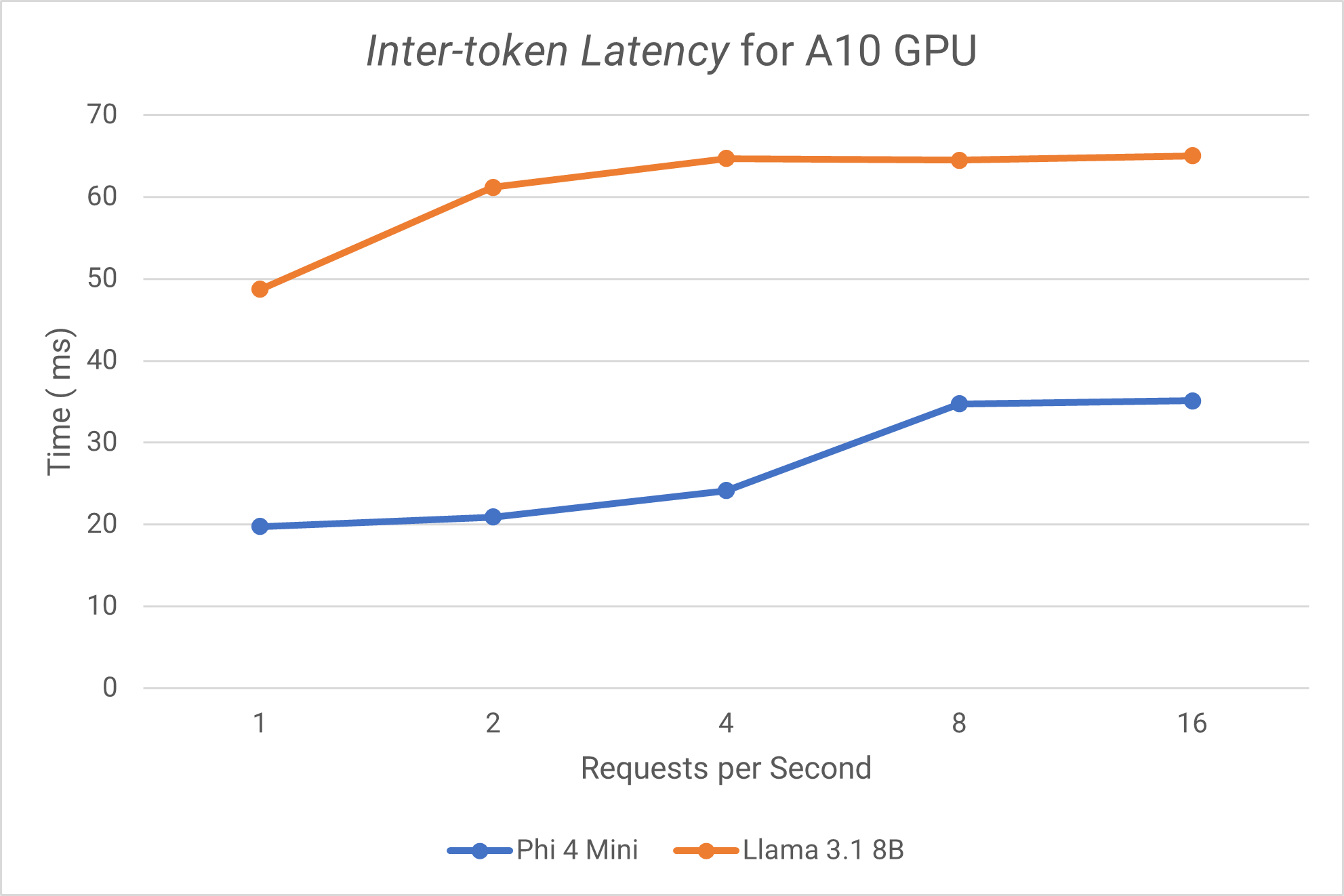
A10 GPU results
Time to First Token
Inter-token Latency
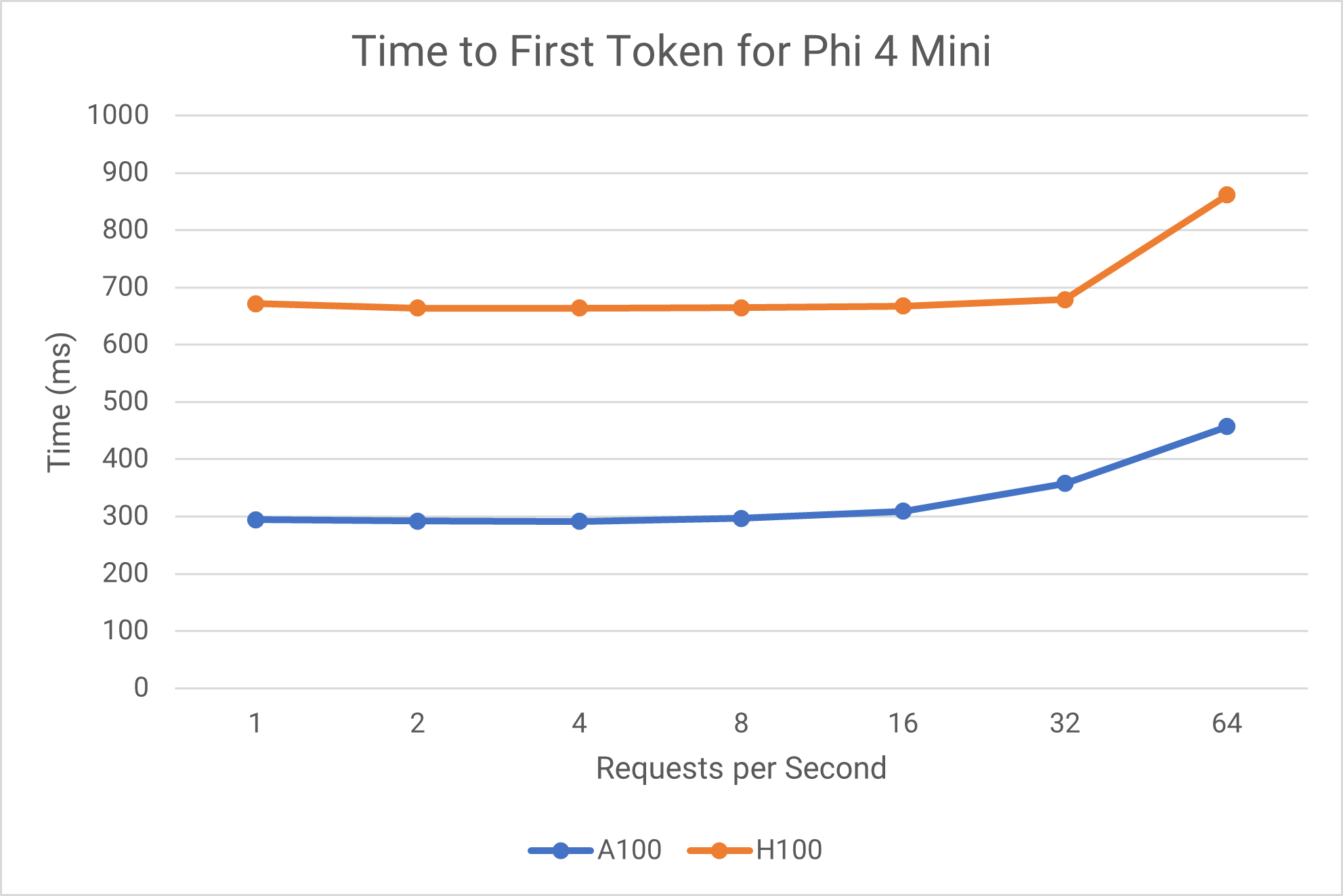
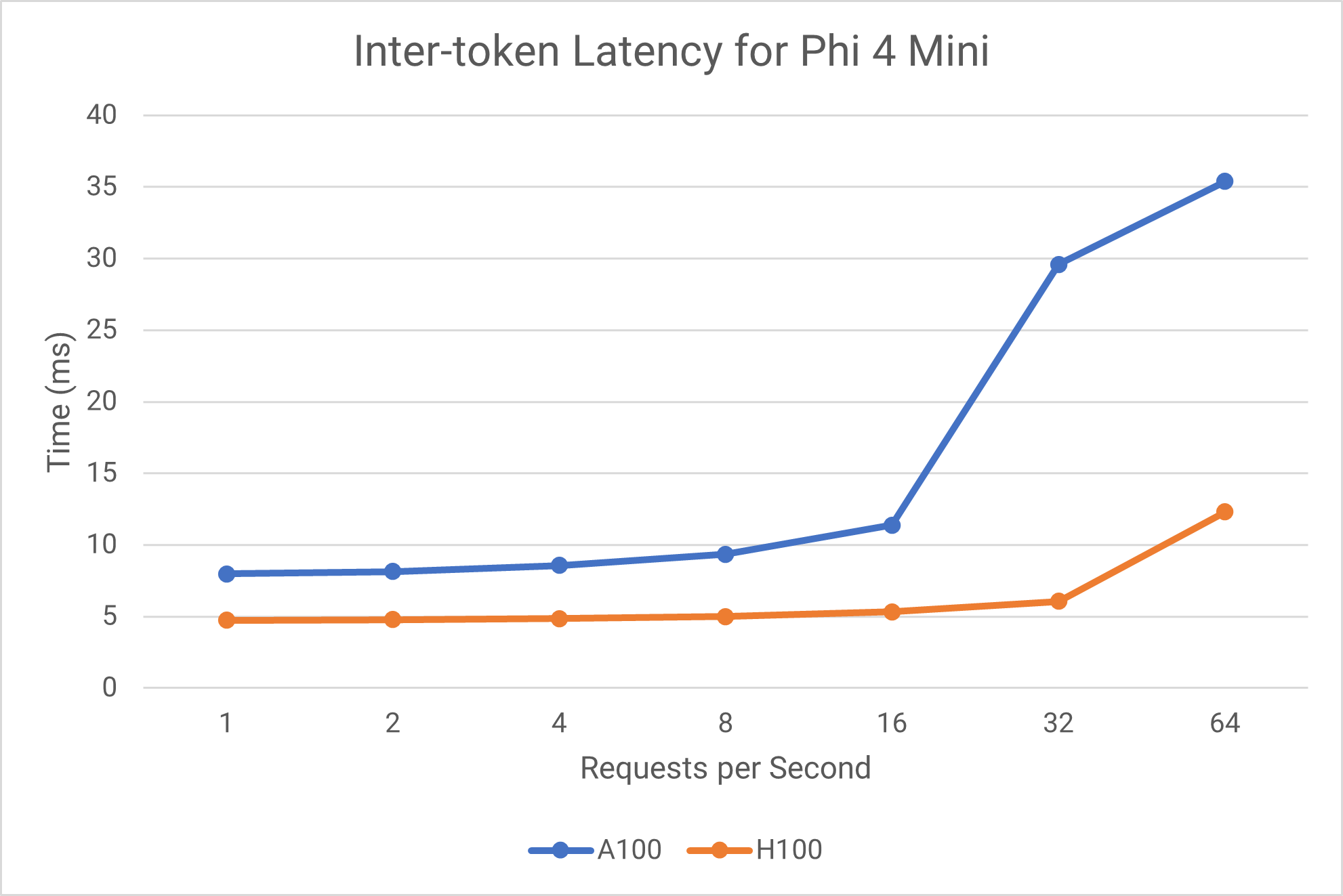
Phi 4 Mini Comparison
Time to First Token
Inter-token Latency
Llama 3.1 8B comparison
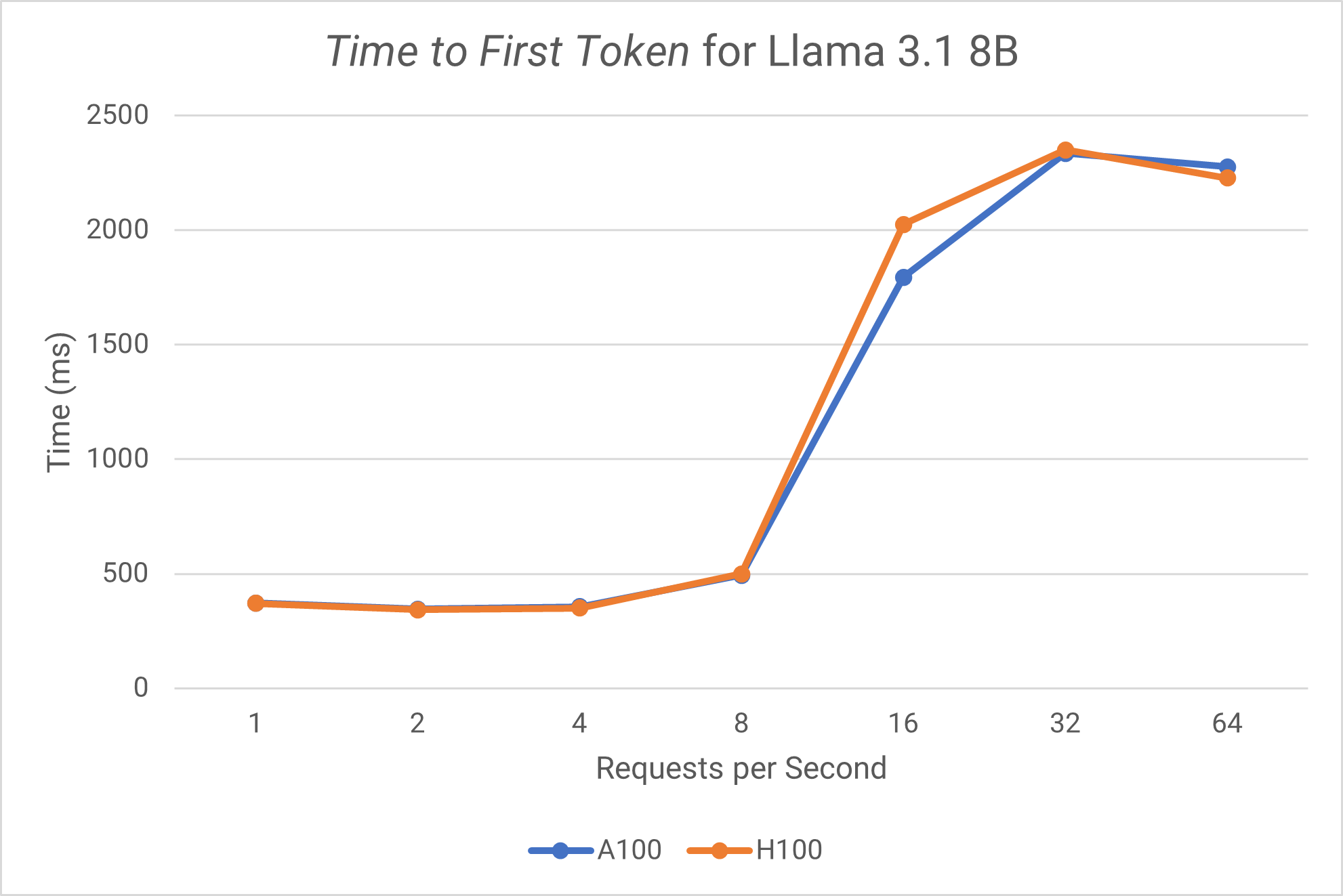
Time to First Token
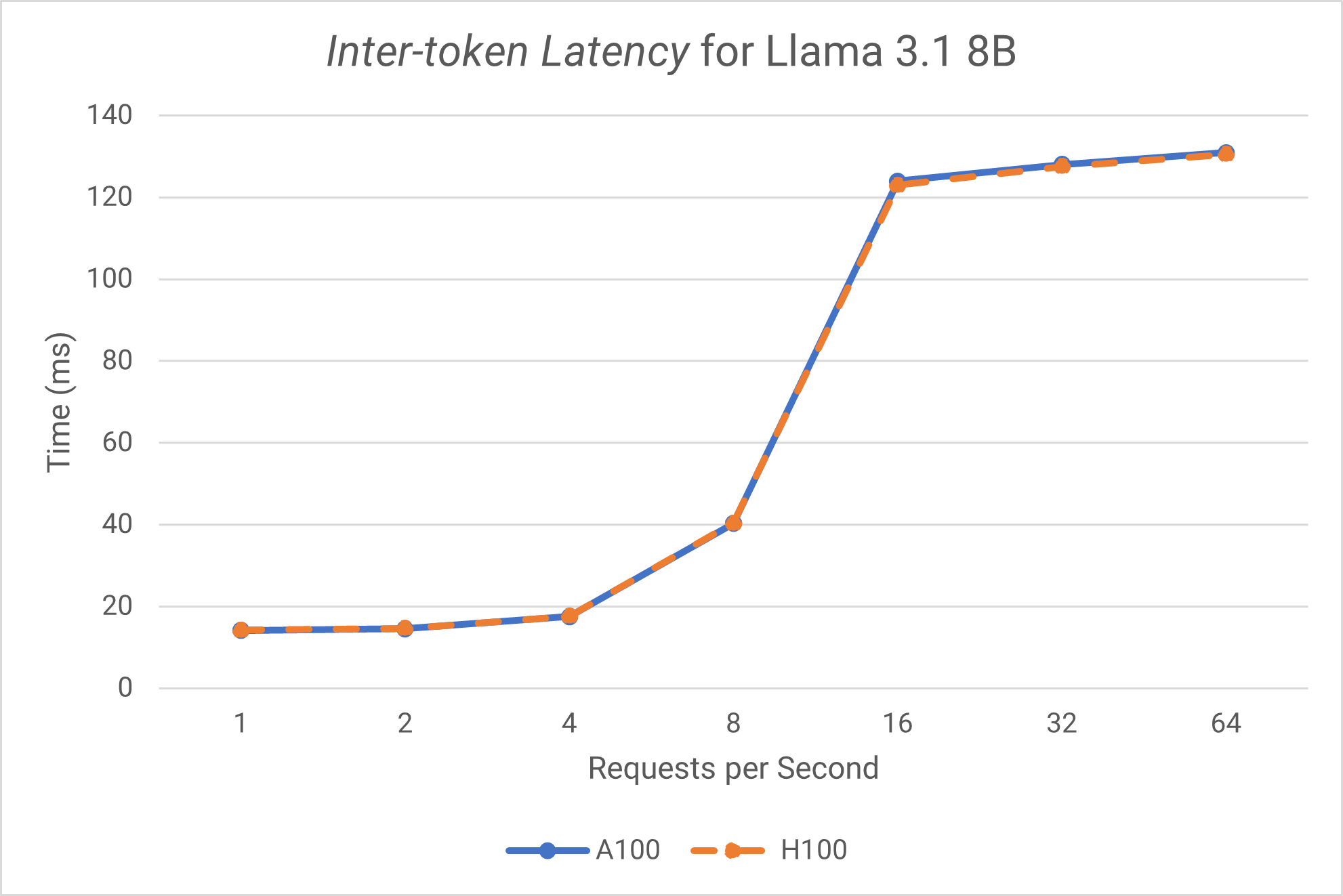
Inter-Token Latency
Performance Analysis
A10 GPU Performance
The A10 GPU performs well on Phi 4 Mini but is not suited for larger models such as Llama 3.1 8B.
Phi 4 Mini on A10:
- TTFT remains stable and fast from (19-35ms)
- ITL is consistent and low (4.78-6.07ms) but begins to grow as request rates increase.
Llama 3.1 8B on A10:
- Shows dramatically higher TTFT (671-20,344) and would result in a considerable wait time.
- ITL grows but remains consistently fast despite the extremely long TTFT.
A100 vs H100 Comparison
Phi 4 Mini Performance
- The H100 almost always has a consistent TTFT of around 600-700 ms, which is surprisingly higher than that of the A100. This is likely because the H100 is meant for larger workloads and a smaller model like this is not optimized to take advantage of its bandwidth.
- The ITL of the H100 is, however, is also consistently lower across all load levels than the A100, which is as expected based as the H100 is a more powerful GPU.
- In terms of scaling, the H100 maintains stable performance up to 32 QPS, then shows degradation at 64 QPS, and the A100 shows more gradual degradation but reaches saturation earlier.
Llama 3.1 8B Performance
- Both GPUs show very similar performance characteristics for this model as TTFT and ITL metrics are very close between the two GPUs.
- Both GPUs handle up to 8 QPS with excellent performance and significant performance jump occurs at 16 QPS, which likely reaches a threshold where batching optimizations kick in.
Recommendations
Cost-Performance Optimization
-
For Phi 4 Mini workloads:
- H100: Recommended for high-throughput production environments requiring low latency
- A100: Cost-effective option for moderate workloads where slight latency increases are acceptable
- A10: Suitable for development, testing, or low-volume production use cases
-
For Llama 3.1 8B workloads:
- A100 and H100: Performance parity makes the A100 the more cost-effective choice
- A10: Can handle the model but limited to short output scenarios
Workload-Specific Guidance
High-Throughput Scenarios (>32 QPS):
- H100 for Phi 4 Mini due to superior scaling characteristics
- Either A100 or H100 for Llama 3.1 8B, with A100 offering better cost efficiency
Latency-Sensitive Applications:
- H100 provides consistently lower TTFT and ITL for Phi 4 Mini
- A100 and H100 perform similarly for Llama 3.1 8B
Budget-Conscious Deployments:
- A10 for light workloads and development
- A100 for production workloads where H100 performance gains don't justify the cost premium
Scaling Considerations
The benchmark results suggest optimal operating ranges:
- Low-load optimal: 1-8 QPS for consistent, predictable performance
- High-throughput optimal: 16-32 QPS where batching optimizations provide maximum efficiency
- Saturation point: Beyond 32-64 QPS, performance gains diminish and latency increases
KAITO is currently adding a feature to distribute the load across model servers when QPS is high to mitigate these issues.
We are currently working on adding automatic scaling across model servers when QPS is high.
Conclusion
These benchmarks demonstrate that GPU selection should be based on specific workload requirements and cost considerations. While the H100 shows superior performance for certain models like Phi 4 Mini, the A100 provides excellent value for models like Llama 3.1 8B where performance parity exists. The A10 serves as an entry-level option for development and light production workloads.
For optimal cost-performance in production environments, we recommend starting with A100 GPUs and scaling to H100 only when the specific performance requirements and throughput demands justify the additional cost.