Inference
This document presents how to use the KAITO workspace Custom Resource Definition (CRD) for model serving and serving with LoRA adapters.
For large models requiring multiple nodes, see the Multi-Node Inference documentation.
Usage
The basic usage for inference is simple. Users just need to specify the GPU SKU used for inference in the resource spec and one of the KAITO supported model name in the inference spec in the workspace custom resource. For example,
apiVersion: kaito.sh/v1beta1
kind: Workspace
metadata:
name: workspace-falcon-7b
resource:
instanceType: "Standard_NC24ads_A100_v4"
labelSelector:
matchLabels:
apps: falcon-7b
inference:
preset:
name: "falcon-7b"
Starting from KAITO v0.9.0, generic Hugging Face models are supported on a best-effort basis. By specifying a Hugging Face model card ID as inference.preset.name in the KAITO workspace, you can run any Hugging Face model with a model architecture supported by vLLM on KAITO. Below is an example illustrating how to create a Hugging Face inference workload using the model card ID Qwen/Qwen3-0.6B from https://huggingface.co/Qwen/Qwen3-0.6B:
apiVersion: kaito.sh/v1beta1
kind: Workspace
metadata:
name: qwen3-06b
resource:
instanceType: Standard_NC24ads_A100_v4
labelSelector:
matchLabels:
apps: qwen3-06b
inference:
preset:
name: Qwen/Qwen3-0.6B
If a user runs KAITO in an on-premise Kubernetes cluster where GPU SKUs are unavailable, the GPU nodes can be pre-configured. The user should ensure that the corresponding vendor-specific GPU plugin is installed successfully in every prepared node, i.e. the node status should report a non-zero GPU resource in the allocatable field. For example:
$ kubectl get node $NODE_NAME -o json | jq .status.allocatable
{
"cpu": "XXXX",
"ephemeral-storage": "YYYY",
"hugepages-1Gi": "0",
"hugepages-2Mi": "0",
"memory": "ZZZZ",
"nvidia.com/gpu": "1",
"pods": "100"
}
Next, the user needs to add the node names in the preferredNodes field in the resource spec. As a result, the KAITO controller will skip the steps for GPU node provisioning and use the prepared nodes to run the inference workload.
The node objects of the preferred nodes need to contain the same matching labels as specified in the resource spec. Otherwise, the KAITO controller would not recognize them.
Inference runtime selection
KAITO now supports both vLLM and transformers runtime. vLLM provides better serving latency and throughput. transformers provides more compatibility with models in the Huggingface model hub.
From KAITO v0.4.0, the default runtime is switched to vLLM. If you want to use transformers runtime, you can specify the runtime in the inference spec using an annotation. For example,
apiVersion: kaito.sh/v1beta1
kind: Workspace
metadata:
name: workspace-falcon-7b
annotations:
kaito.sh/runtime: "transformers"
resource:
instanceType: "Standard_NC24ads_A100_v4"
labelSelector:
matchLabels:
apps: falcon-7b
inference:
preset:
name: "falcon-7b"
Multi-node distributed inference is currently supported only with the vLLM runtime. For details on configuring multi-node deployments, see Multi-Node Inference.
Inference with custom parameters
Users can customize vLLM runtime parameters by creating a ConfigMap containing an inference_config.yaml file and referencing it in the workspace spec. For example:
apiVersion: v1
kind: ConfigMap
metadata:
namespace: myns
name: my-inference-params
data:
inference_config.yaml: |
max_probe_steps: 6
vllm:
gpu-memory-utilization: 0.95 # Controls GPU memory usage (0.0-1.0)
tensor-parallel-size: 2 # Number of GPUs for tensor parallelism
max-model-len: 131072 # Maximum sequence length
swap-space: 4 # CPU swap space in GB
cpu-offload-gb: 0 # Amount of GPU memory to offload to CPU
---
apiVersion: kaito.sh/v1beta1
kind: Workspace
metadata:
namespace: myns
name: workspace-example
resource:
instanceType: "Standard_NC24ads_A100_v4"
labelSelector:
matchLabels:
apps: example
inference:
preset:
name: "example-model"
config: "my-inference-params" # Reference to ConfigMap name
Key vLLM parameters include:
gpu-memory-utilization: Controls fraction of GPU memory allocated (between 0.0 and 1.0)tensor-parallel-size: Number of GPUs to use for tensor parallelismmax-model-len: Maximum sequence length the model can handle
For the complete list of vLLM parameters, refer to the vLLM documentation.
Inference with LoRA adapters
KAITO also supports running the inference workload with LoRA adapters produced by model fine-tuning jobs. Users can specify one or more adapters in the adapters field of the inference spec. For example,
apiVersion: kaito.sh/v1beta1
kind: Workspace
metadata:
name: workspace-falcon-7b
resource:
instanceType: "Standard_NC24ads_A100_v4"
labelSelector:
matchLabels:
apps: falcon-7b
inference:
preset:
name: "falcon-7b"
adapters:
- source:
name: "falcon-7b-adapter"
image: "<YOUR_IMAGE>"
strength: "0.2"
Currently, only images are supported as adapter sources. The strength field specifies the multiplier applied to the adapter weights relative to the raw model weights.
Note: When building a container image for an existing adapter, ensure all adapter files are copied to the /data directory inside the container.
For detailed InferenceSpec API definitions, refer to the documentation.
Inference API
The OpenAPI specification for the inference API is available at vLLM API, transformers API.
vLLM inference API
vLLM supports OpenAI-compatible inference APIs. Check here for more details.
Transformers inference API
The transformers runtime now uses an OpenAI-compatible API powered by the HuggingFace transformers serve engine.
Chat Completions
curl -X POST "http://<SERVICE>:80/v1/chat/completions" \
-H "Content-Type: application/json" \
-d '{
"model": "MODEL_NAME",
"messages": [{"role": "user", "content": "YOUR_PROMPT_HERE"}],
"max_tokens": 200,
"temperature": 0.7
}'
Responses API
curl -X POST "http://<SERVICE>:80/v1/responses" \
-H "Content-Type: application/json" \
-d '{
"model": "MODEL_NAME",
"input": "YOUR_PROMPT_HERE",
"max_output_tokens": 200
}'
List Models
curl -X GET "http://<SERVICE>:80/v1/models"
For the full list of supported parameters, refer to the OpenAI API reference and the HuggingFace transformers serve documentation.
Inference workload
Depending on whether the specified model supports distributed inference or not, the KAITO controller will choose to use either Kubernetes apps.deployment workload (by default) or Kubernetes apps.statefulset workload (if the model supports distributed inference) to manage the inference service, which is exposed using a Cluster-IP type of Kubernetes service.
For multi-node distributed inference, KAITO uses StatefulSets to ensure stable pod identity and coordination between leader and worker pods. See Multi-Node Inference for detailed architecture information.
When adapters are specified in the inference spec, the KAITO controller adds an initcontainer for each adapter in addition to the main container. The pod structure is shown in Figure 1.
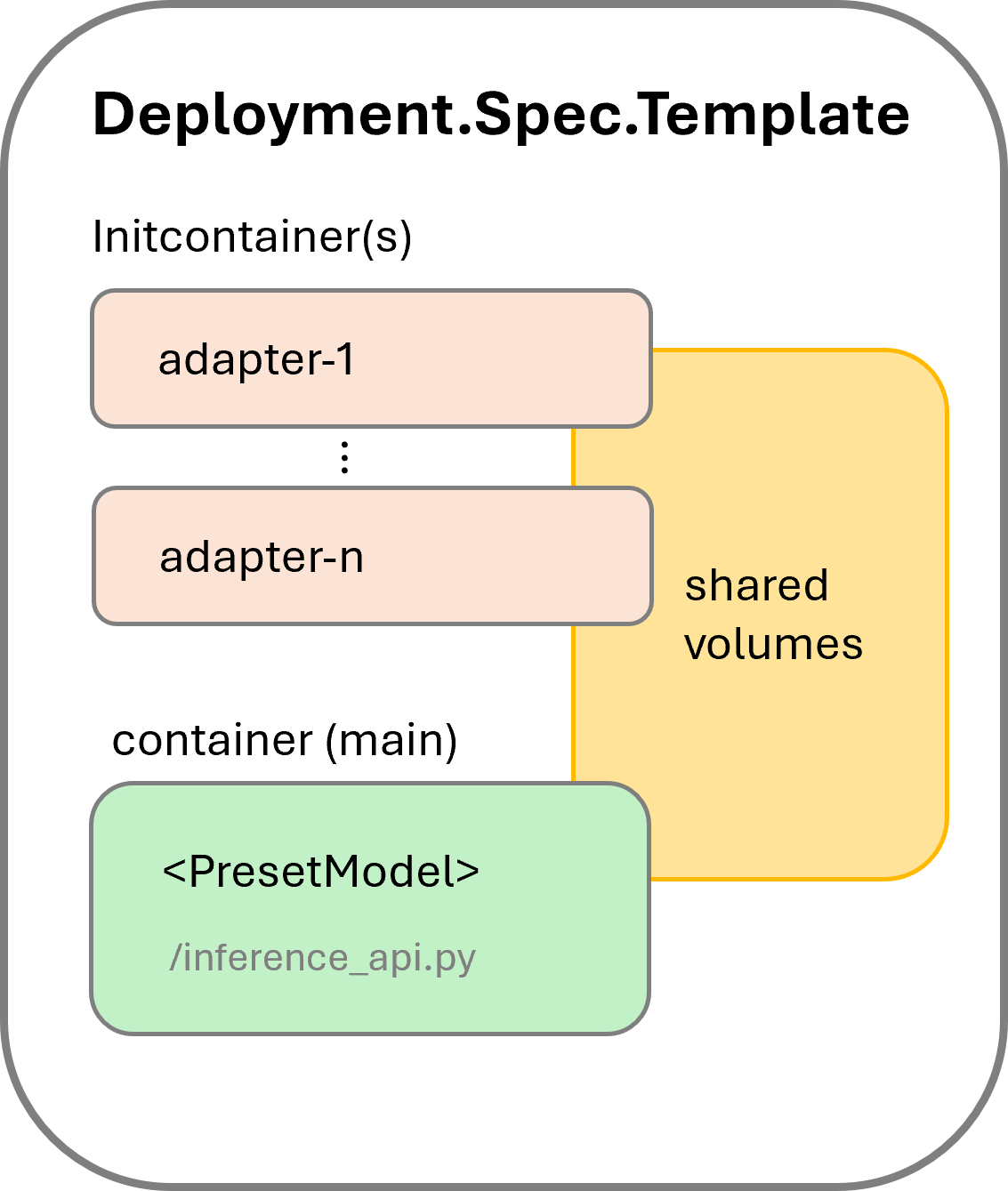
If an image is specified as the adapter source, the corresponding initcontainer uses that image as its container image. These initcontainers ensure all adapter data is available locally before the inference service starts. The main container uses a supported model image, launching the inference_api.py script.
All containers share local volumes by mounting the same EmptyDir volumes, avoiding file copies between containers.
Workload update
To update the adapters field in the inference spec, users can modify the workspace custom resource. The KAITO controller will apply the changes, triggering a workload deployment update. This will recreate the inference service pod, resulting in a brief service downtime. Once the new adapters are merged with the raw model weights and loaded into GPU memory, the service will resume.
Troubleshooting
TBD